View and download the notebook here!
Keane and Wolpin (1997)#
Parameter Estimation via the Method of Simulated Moments (MSM)
In their seminal paper on the career decisions of young men, Keane and Wolpin (1997) estimate a life-cycle model for occupational choice based on NLSY data for young white men. The paper contains a basic and an extended specification of the model. Both models allow for five choice alternatives in each period: white collar sector work, blue collar sector work, military work, school, and staying home. Choice options come with pecuniary and/or non-pecuniary rewards. Agents are assumed to be forward-looking and act under uncertainty because of the occurrence of alternative-specific shocks that affect the current reward of alternatives and only become known to individuals in the period they occur in. Individuals thus form expectations about future shocks and in each period choose the option that maximizes the expected present value of current and future lifetime rewards.
The extended model compared to the base specification expands the model by introducing more complex skill technology functions that for example allow for skill depreciation and age effects, job mobility and search costs, non-pecuniary rewards for work, re-entry costs for school, and some common returns for school.
respy is able to solve, simulate, and estimate both model specifications. Within respy, they are referred to as kw_97_basic and kw_97_extended. However, using the parameters from the paper, respy returns life-cycle patterns that differ from the ones presented in the paper, prompting us to re-estimate them using the Method of Simulated Moments (MSM). The model specification can be loaded using the function get_example_model as demonstrated below. The returned parameter
vector contains the estimated parameters from the paper and the returned DataFrame contains the ‘observed’ NLSY data.
[2]:
import numpy as np
import pandas as pd
import respy as rp
import matplotlib.pyplot as plt
[12]:
params_basic_kw, options, data_obs = rp.get_example_model("kw_97_basic")
Choice patterns and Rewards for Parameters in kw_97_basic#
To investigate the parameter specification presented for the basic model in Keane and Wolpin (1997), we will look at the choice frequencies in each period and compare them to the observed data. While the NLSY data is only observed for the first 11 years, the models can be used to predict choices over the entire work life of agents. The standard time horizon in kw_97_basic is 50 periods since Keane and Wolpin (1997) fix the terminal age to 65 with individuals entering the sample at age 15. We
will thus inspect how well the model generated by the parameters can fit the observed data, as well as the predictions it makes for the rest of the life-cycle.
Choice Patterns#
As a first step, we will look at the choices of agents over time. To do this, we can simulate data based on the parameters from kw_97_basic and compute the choice frequencies in each period. We then plot them against the observed choices.
[18]:
simulate = rp.get_simulate_func(params_basic_kw, options)
[19]:
data_sim_kw = simulate(params_basic_kw)
[8]:
def calc_choice_frequencies(df):
"""Compute choice frequencies."""
return df.groupby("Period").Choice.value_counts(normalize=True).unstack()
[13]:
choices_obs = calc_choice_frequencies(data_obs)
[20]:
choices_obs = calc_choice_frequencies(data_obs)
choices_kw = calc_choice_frequencies(data_sim_kw)
[10]:
def plot_moments(moments_obs, moments_sim, labels, colors):
"""Plot moments."""
plt.figure(figsize=(14, 4))
for i, (label, color) in enumerate(zip(labels, colors)):
plt.subplot(1, 5, i + 1)
plt.tight_layout()
plt.title(label.capitalize())
plt.xlabel("Period")
plt.plot(moments_sim[label], color=color)
plt.plot(moments_obs[label], color="black", linestyle="dashed")
plt.ylim(0, 1)
plt.xlim(0, 50)
[16]:
choices = ["blue_collar", "white_collar", "school", "home", "military"]
colors = ["tab:blue", "tab:orange", "tab:green", "tab:red", "tab:purple"]
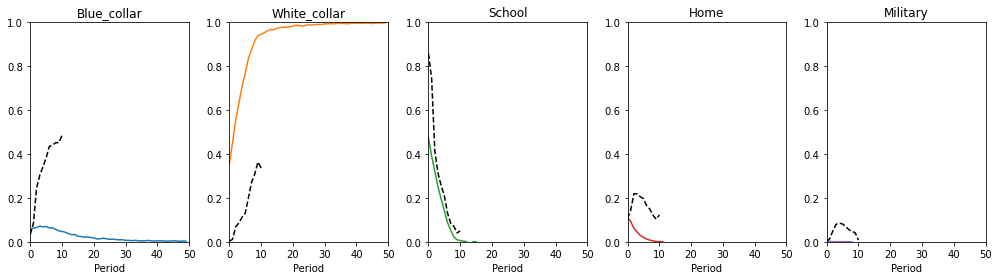
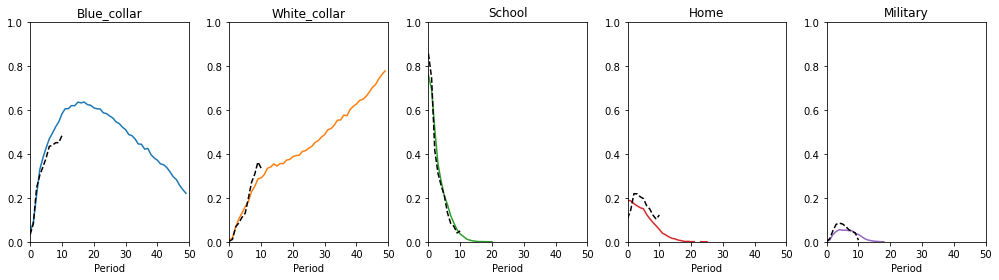
The plots below show the choice frequencies of individuals for the five different choice alternatives. The colored lines represent the simulated dataset while the black dotted lines show the choices observed in the NLSY data. The simulated data does not seem to fit the observed data very well. The percentage of individuals choosing the white collar occupation is too high while all other choices are very underrepresented in the simulated data.
[10]:
plot_moments(
moments_obs=choices_obs, moments_sim=choices_kw, labels=choices, colors=colors,
)
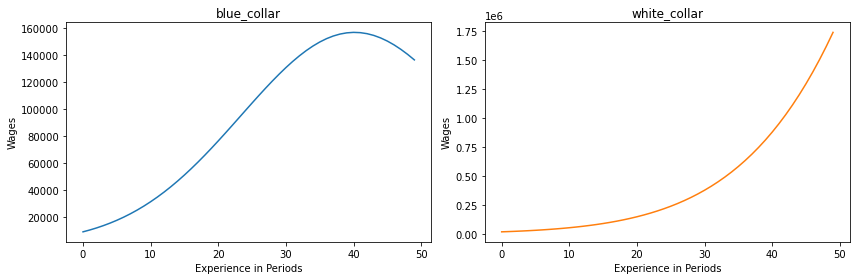
Experience-Wage Profiles over the Life-Cycle#
As a next step, we will inspect the experience-wage profiles suggested by the model. The function below computes the wages of a skill type 0 individual (skill endowment types are a source of heterogeneity between individuals in the model) with 10 years of schooling for the given wage parameters if they enter an occupation in period 0 and stay in that occupation for their entire life-cycle.
[11]:
def get_experience_profile(params, options, occupation):
# To fix ideas we look at a Type 0 individual with 10 years of schooling
# who immediately starts to work in the labor market.
covars = [1, 10, 0, 0, 0, 0, 0, 0, 0]
wages = list()
for period in range(options["n_periods"]):
if occupation == "blue_collar":
covars[3] = period
covars[4] = period ** 2 / 100
elif occupation == "white_collar":
covars[2] = period
covars[3] = period ** 2 / 100
wage = np.exp(np.dot(covars, params.loc[f"wage_{occupation}", "value"]))
wages.append(wage)
return wages
[12]:
def plot_experience_profiles(params, options):
colors = ["tab:blue", "tab:orange"]
occupations = ["blue_collar", "white_collar"]
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
for i, (label, color) in enumerate(zip(occupations, colors)):
wage_profile = get_experience_profile(params, options, label)
ax[i].plot(range(options["n_periods"]), wage_profile, color=color)
ax[i].set_xlabel("Experience in Periods")
ax[i].set_ylabel("Wages")
ax[i].set_title(label)
plt.tight_layout()
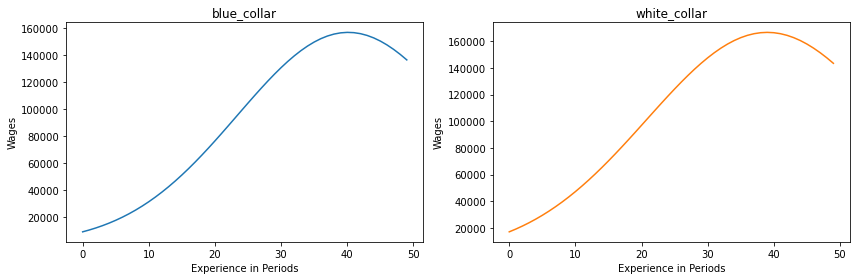
We can then plot the wage-experience profiles of the three occupations. The wage profiles do not seem very realistic, as especially the white collar occupation sees unlimited wage growth into the millions. The curve is missing the characteristic flattening (slowed and sometimes even negative wage growth) in later stages of life that is well documented in the life-cycle wage literature (Heckman et al., 2006).
The military option is purposely left out in this plot since the low number of observations in the NLSY data for this occupation does not allow for the construction of an appropriate experience-wage profile.
[13]:
plot_experience_profiles(params_basic_kw, options)
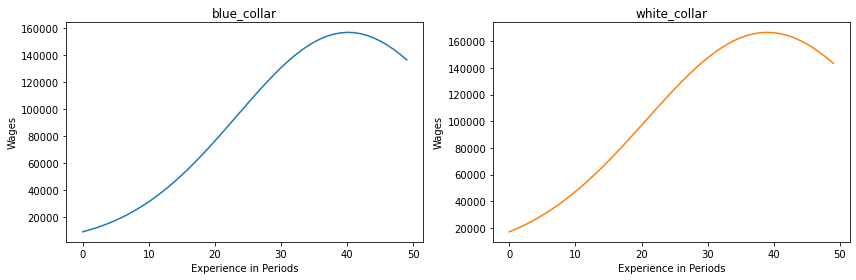
Since this flattening characteristic is controlled by the exponential term in the wage equation, we can see if adjusting this parameter improves the wage profile for the white collar occupation. The parameter specification in the paper gives this parameter a value of -0.0461. We will choose a smaller value in an attempt to flatten the curve in later periods.
[14]:
params_new = params_basic_kw.copy()
params_new.loc[("wage_white_collar", "exp_white_collar_square"), "value"] = -0.15
As the plots below show, the new value for (wage_white_collar, exp_white_collar_square) produces a more realistic wage profile and wage for the white collar occupation:
[15]:
plot_experience_profiles(params_new, options)
Estimation of the Basic Model#
Since there seems to be a possibility of improvements, we attempt to estimate the parameters via MSM to improve the fit. The estimation setup for MSM follows the pattern already established in other articles of this documentation. For the estimation we use moments that capture the choice frequencies for each period and mean wages as well as their standard deviation. The weighting matrix used is a diagonal inverse variance weighting matrix. Interested readers can refer to the guides below for
more information on MSM estimation with respy.
Choice Patterns#
We will first investigate the choice patterns of individuals over the 11 observed periods and the predicted choices in later periods. The plot below shows the choice frequencies for the observed data and simulated data for the specification in Keane and Wolpin (1997) and our estimates respectively in a stacked area plot. The newly estimated parameters are named with the suffix _respy.
[16]:
params_basic_respy, _, _ = rp.get_example_model("kw_97_basic_respy")
[17]:
data_sim_new = simulate(params_basic_respy)
[18]:
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(15, 5))
calc_choice_frequencies(data_sim_kw)[choices].plot(
kind="area",
stacked=True,
ax=axes[0],
xlim=[0, 11],
title="Simulated Choices KW 97",
linewidth=0.1,
)
calc_choice_frequencies(data_obs)[choices].plot(
kind="area", stacked=True, ax=axes[1], title="Observed Choices", linewidth=0.1
)
calc_choice_frequencies(data_sim_new)[choices].plot(
kind="area",
stacked=True,
ax=axes[2],
xlim=[0, 11],
title="Simulated Choices New Estimates",
linewidth=0.1,
)
[18]:
<AxesSubplot:title={'center':'Simulated Choices New Estimates'}, xlabel='Period'>
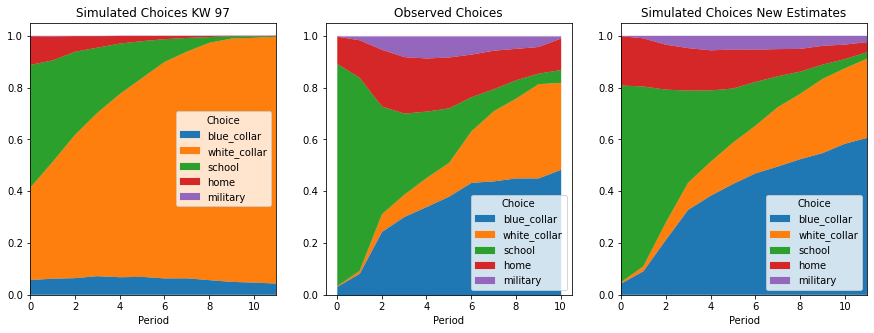
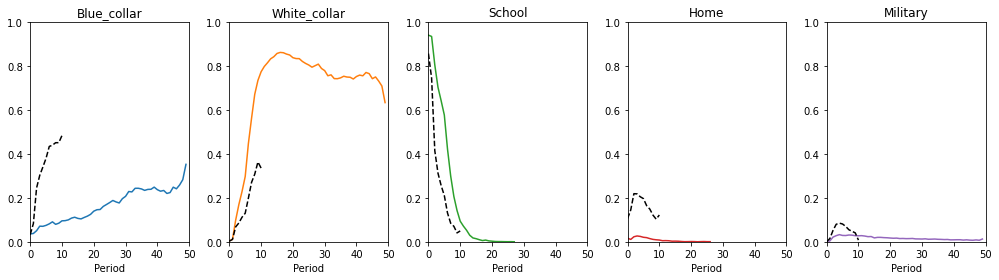
Plotting the choices separately against their observed counterpart also reveals a much better fit.
[19]:
choices_new = calc_choice_frequencies(data_sim_new)
[20]:
plot_moments(
moments_obs=choices_obs, moments_sim=choices_new, labels=choices, colors=colors,
)
Experience-Wage Profiles#
The wage profiles have attained a more realistic shape although the earned wages in later periods are still unreasonably high. These problems in wage growth are similar to the ones shown by Keane and Wolpin (1997) for the basic specification and give way to the expanded model, which promises a more reasonable development of life-cycle wages.
[21]:
plot_experience_profiles(params_new, options)
Estimation of the Extended Model#
In addition to the basic model parameters, we also re-estimate the extended model specified in Keane and Wolpin (1997). Since the parameter space for this model is much larger than the basic specification, we expand the number of moments used for estimation. The new sets of moments used are conditional on the period and initial level of schooling of individuals. Specifically, we compute the choice frequencies and wage statistics for two initial schooling groups: those with up to 9 years of schooling at age 16 and those with 10 years or more. Furthermore, the moments for the wage distribution are expanded to include the median and 25% as well as 75% percentile for each initial schooling group in each period.
The plots below show the choice frequencies for the parameters from the paper and the newly estimated parameters. While the fit seems much better for the newly estimated parameters, the choice patterns they suggest over the life-cycle in some cases are a bit more extreme than the ones presented in Keane and Wolpin (1997), especially for the blue and white collar occupations.
This is not necessarily surprising as the model is fit on only 11 years of data, while the extrapolation is applied to 50 periods. Multiple other parameter estimates (not shown here) with a similar within-sample fit predict very different choice patterns over the life-cycle. The parameters presented here should thus be used and interpreted with caution.
[3]:
params_extended_kw, options_extended, _ = rp.get_example_model("kw_97_extended")
[4]:
simulate_extended = rp.get_simulate_func(params_extended_kw, options_extended)
[6]:
data_sim_extended_kw = simulate_extended(params_extended_kw)
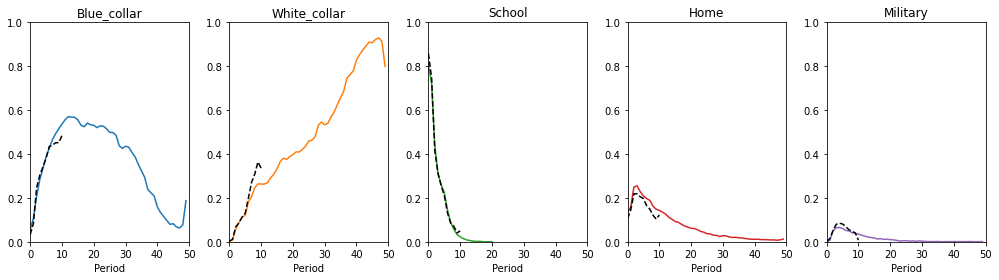
Choice Frequencies for Extended Parametrization from Keane and Wolpin (1997)#
[13]:
choices_extended_kw = calc_choice_frequencies(data_sim_extended_kw)
plot_moments(
moments_obs=choices_obs, moments_sim=choices_extended_kw, labels=choices, colors=colors,
)
Choice Frequencies for Estimated Extended Parameters#
[5]:
params_extended_respy, _, _ = rp.get_example_model("kw_97_extended_respy")
[6]:
data_sim_extended_respy = simulate_extended(params_extended_respy)
[17]:
choices_extended_respy = calc_choice_frequencies(data_sim_extended_respy)
plot_moments(
moments_obs=choices_obs, moments_sim=choices_extended_respy, labels=choices, colors=colors,
)
References#
Heckman, J. J., Lochner, L. J., & Todd, P. E. (2006). Earnings functions, rates of return and treatment effects: The Mincer equation and beyond. In Hanushek, E. & Welch, F., editors, Handbook of the Economics of Education, volume 1, pages 307–458. Elsevier Science, Amsterdam, Netherlands.
Keane, M. P. and Wolpin, K. I. (1997). The Career Decisions of Young Men. Journal of Political Economy, 105(3): 473-522.